
Adansons Base ( ~ July)
Adansons Base (日本語ページ) ← 🇯🇵 Japanese Page
Product Concept
- Adansons Base is a data programming tool that organizes metadata of unstructured data and creates and manages datasets.
- It makes dataset creation more effective and helps to find low-quality data by using the training results and improves AI performance.

View tutorial on GitHub
DEMO
Feature 1: Collects the useful information for dataset creation into the database.
Adansons Base automatically extracts the information contained in data file paths and file names, as well as attribute information (metadata) related to data described in external files such as Excel, and organizes the dataset into a form ready to train on it.
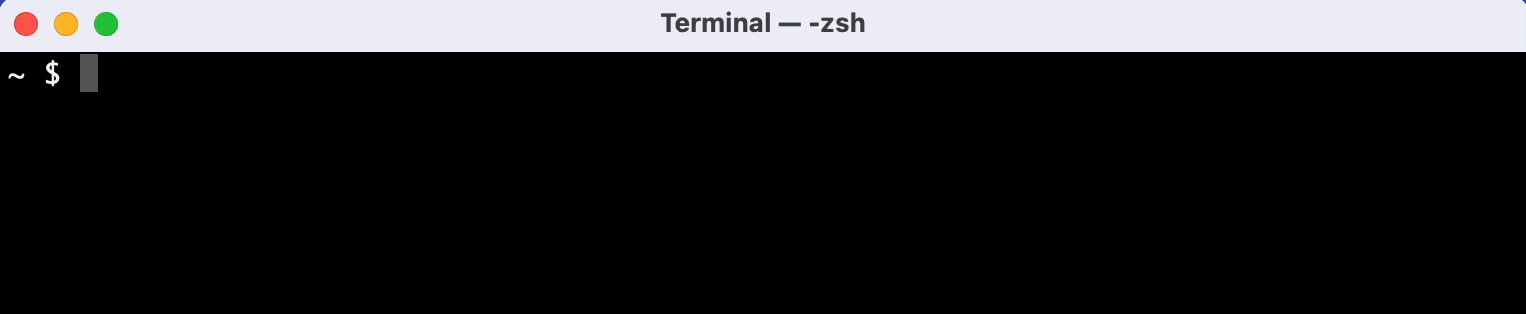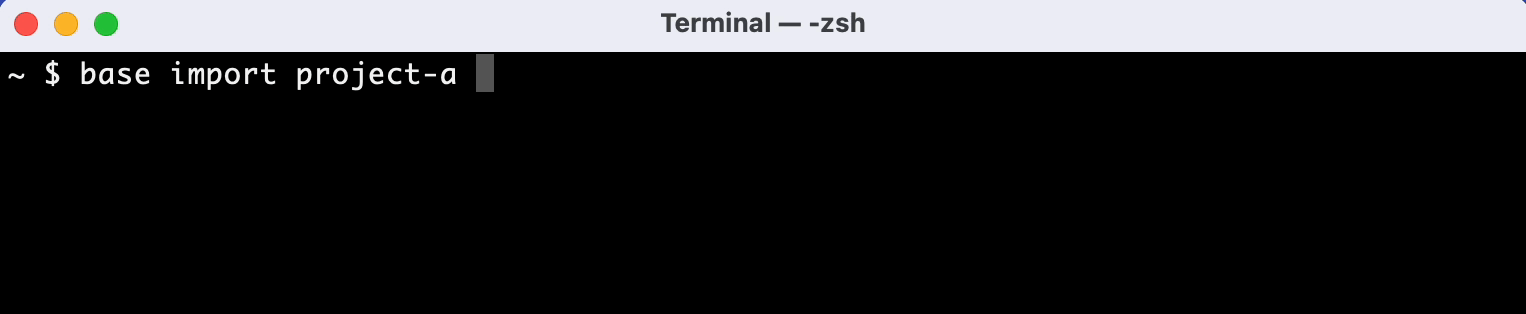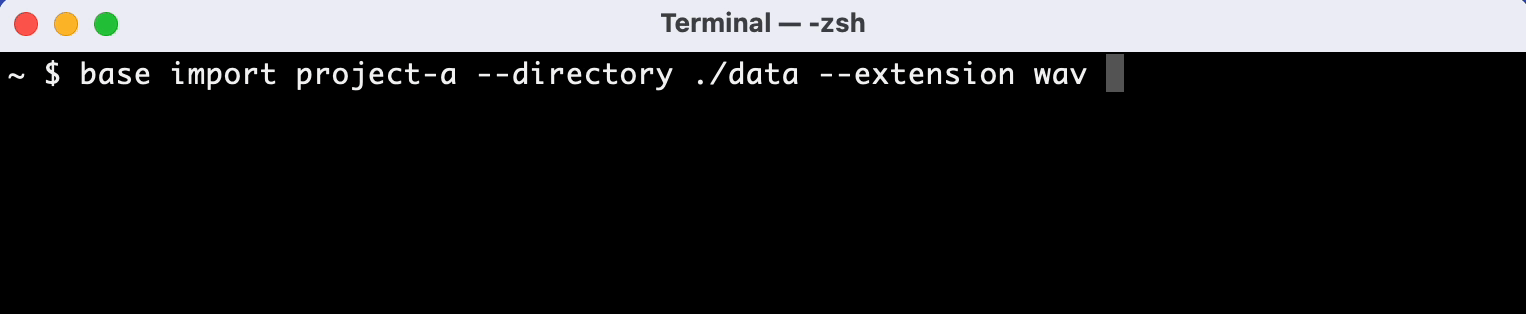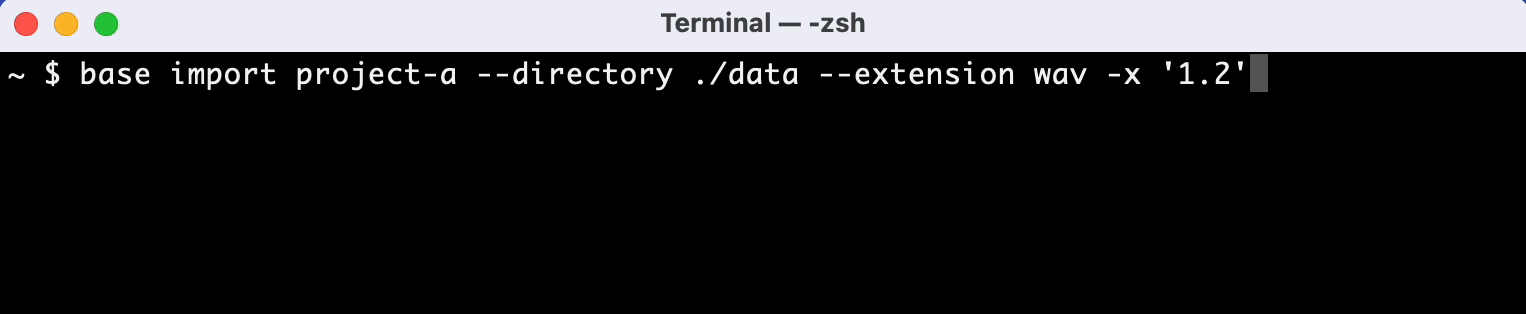
Recognizes duplicate metadata and labeling mistakes and integrates automatically
In addition, it automatically detects duplicate information in data files and integrates it into the database.
If you have data files like this for example, Adansons Base automatically combines columns
"identifier" and "id", and
"class" and "class name".

Information Adansons Base integrates
- file paths and folder names
- information related to training data in Excel and CSV files
- information related to training results of ML models and parameters
*The data file itself is left with the customer, and only the above information is collected.


Feature 2: Reduce the time for dataset creation.
Exported databases are compatible with various ML frameworks
With the SDK, you can export the dataset in a format that can be used immediately with PyTorch and Keras.
You don’t have to write a Dataloader anymore.

Adansons base converts data into a standardized format that is familiar to you, so that you can smoothly use it.
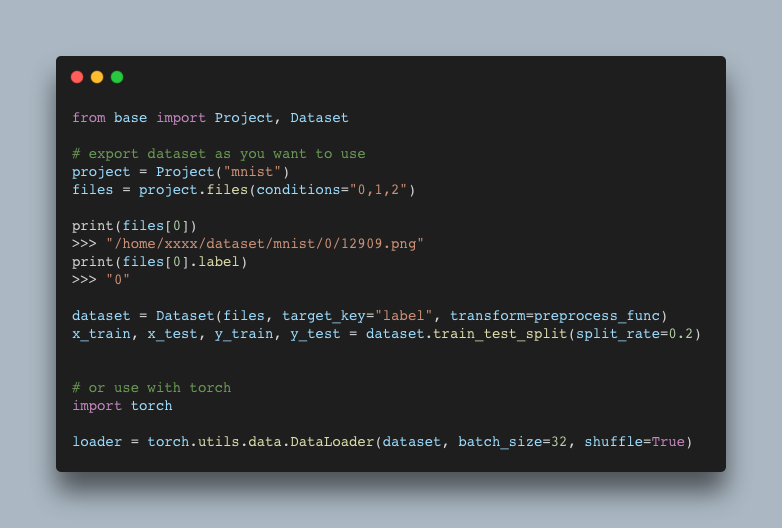
Training results can also be reflected in dataset creation
The training results can also be easily collected in the database. For example using training results, it is possible to remove only the data that brings bad prediction results.

Export the dataset in URL and CSV format
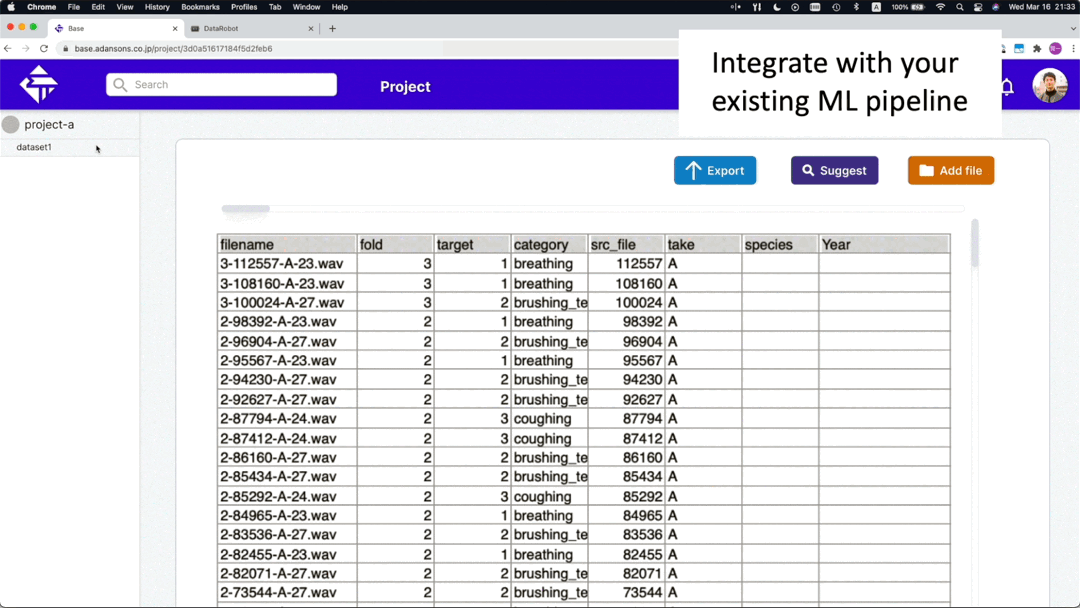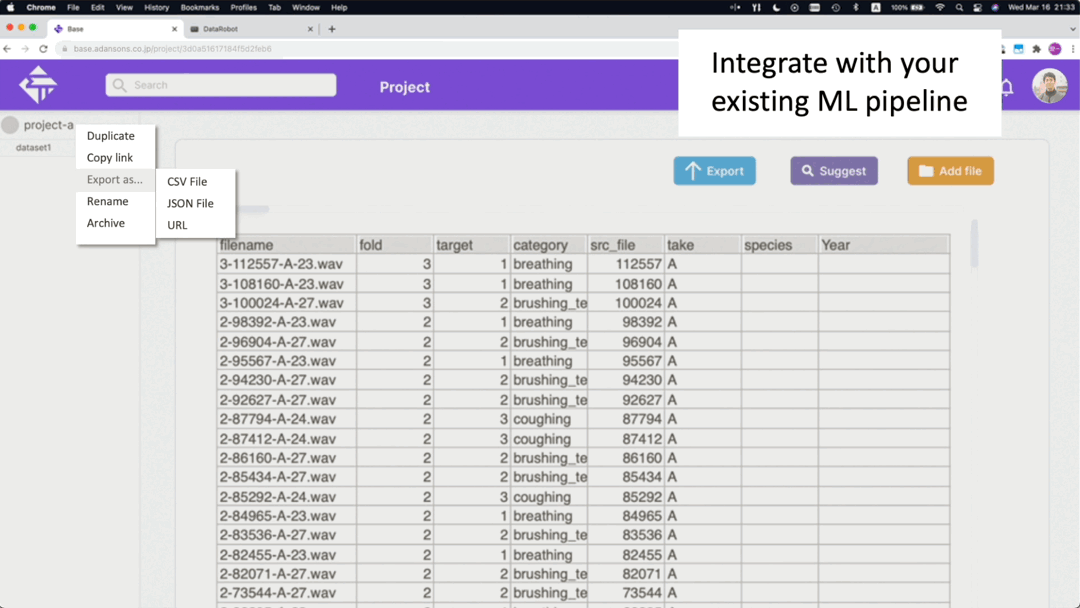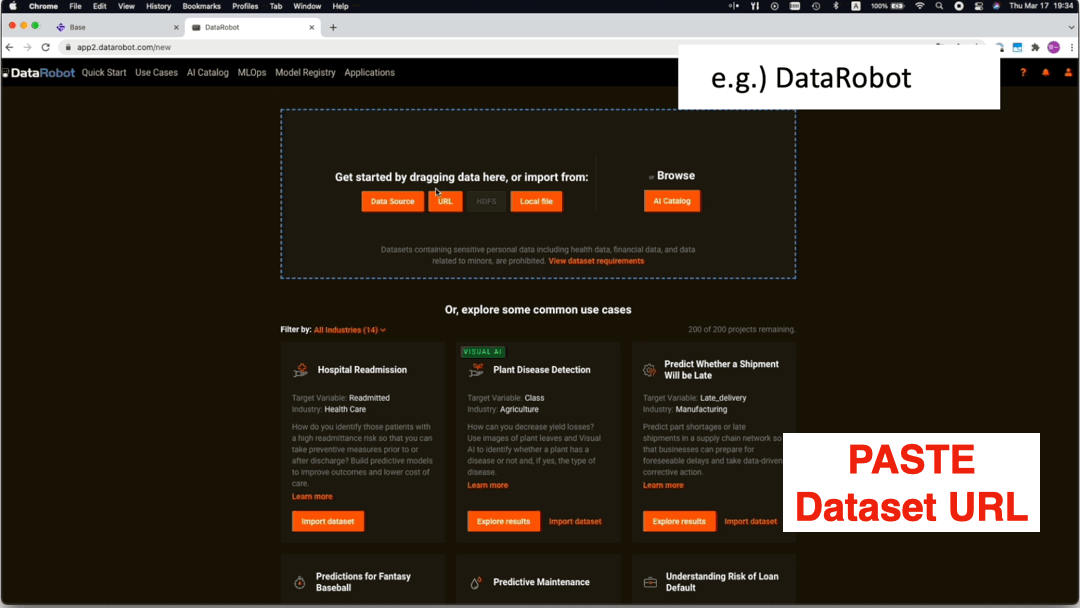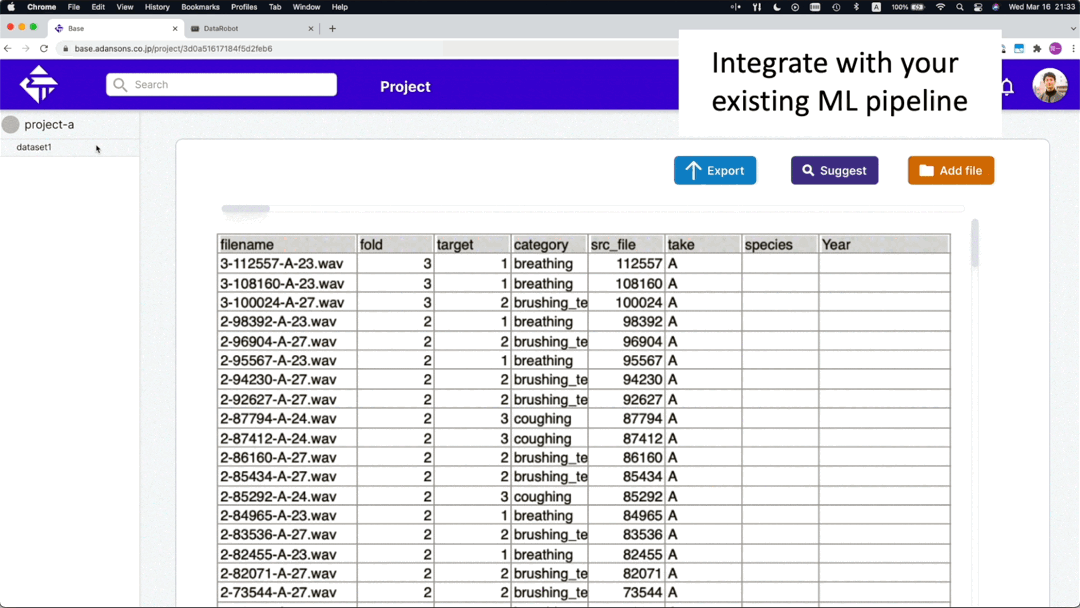
Feature 3: Share datasets quickly.
Once created, the dataset can be easily shared with others, which allows them to immediately start using the most recent version
Information necessary for training other than data files can be passed on using Adansons Base like cloud storage.

Feature 4: Support improving dataset quality for better AI performance.
Find and suggest factors that reduce the performance of AI (*β version, PCT international application pending.)
This functionality uses the AI's training results and the critical information contained in the dataset.
It is a recommendation engine that enables customers to easily develop data-centric AI.
It compares the AI's training results with labels and other collected metadata and finds out the factors that degrade the performance from various perspectives.
Not only model-centric but also data-centric AI development will be easier.
Using Adansons Base, you can get suggestions such as the following.
“This data of label C looks like low quality.”
“Some have good prediction accuracy and some have poor prediction accuracy, so they should be divided into two classes, foo and bar, respectively”.
“Changing parameters A and B in the model leads to higher prediction accuracy than changing parameter C.”
Once the user has decided which suggestions to accept, the dataset is immediately available to Jupyter and others.

Plans & Pricing
✉️ Register from here to use!
Fill in the following form to use Adansons Base!
↓↓↓
Contact Us
Please feel free to contact us with any questions you may have.
support[at]adansons.co.jp
replace [at] with @
Copyright © Adansons Inc., 2022, All Rights Reserved.